Ingénierie de la confiance en IA de flotte : prévention en temps réel, fiabilité et supervision humaine là où cela compte
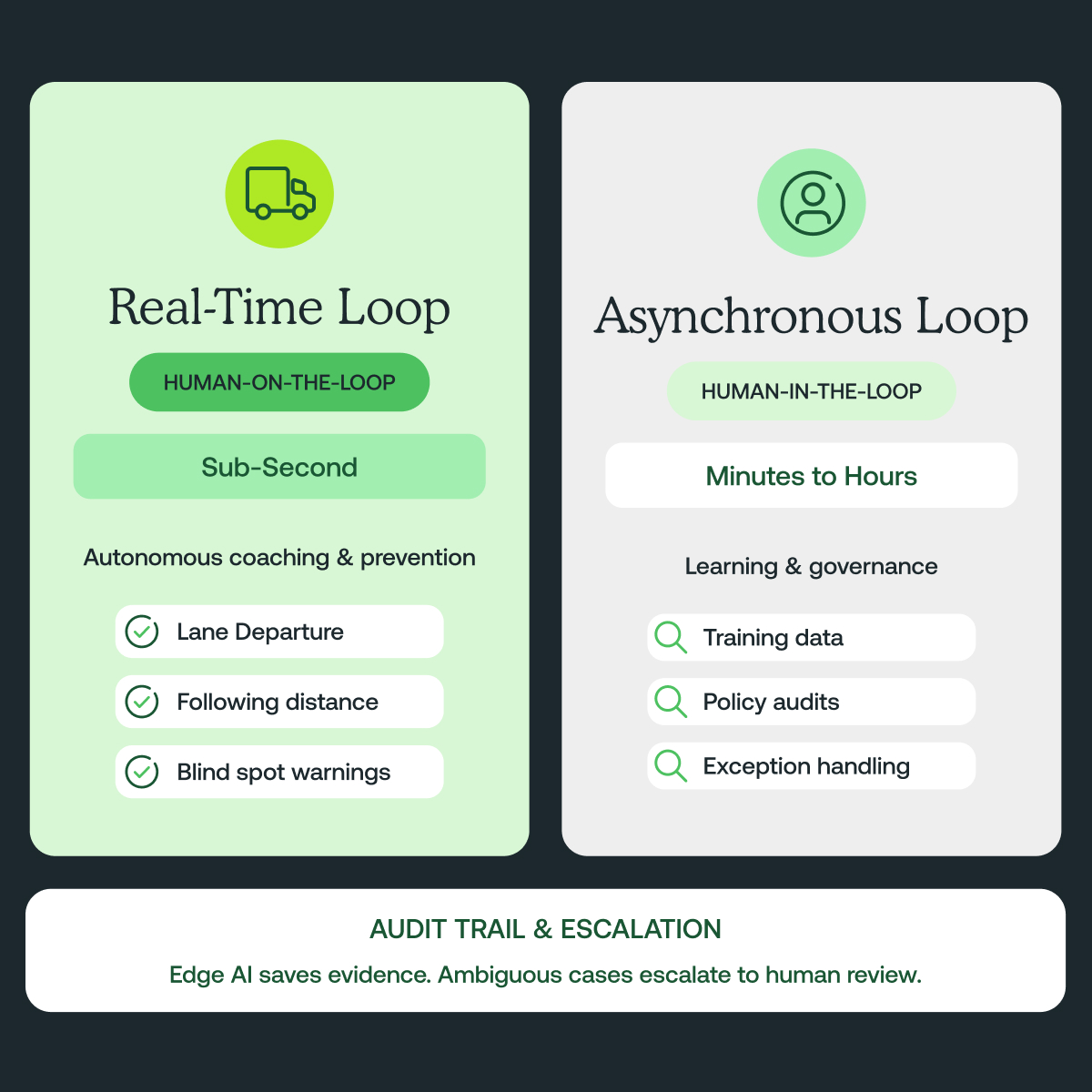
L'humain dans la boucle (HITL) joue un rôle critique dans la validation de modèle, l'audit et l'amélioration continue pour la sécurité et les opérations de flotte. Cependant, en temps réel, dans des scénarios critiques de sécurité, HITL n'est pas approprié comme chemin de contrôle principal en raison de la latence inévitable et des contraintes opérationnelles. Dans la conduite du monde réel, les boucles de décision sont inférieures à une seconde, la connectivité est intermittente, et l'atténuation des risques doit s'exécuter de manière prévisible et constante sur le véhicule, à la périphérie. Conçues pour une opération haute confiance en temps réel, ces architectures ont prouvé aider à réduire les incidents évitables, réduire la charge de révision vidéo et soutenir des enquêtes plus rapides.
Pour le coaching de conducteur en temps réel et la prévention de collision, un humain ne peut pas être « dans la boucle » à l'exécution. La fiabilité système doit être intégrée directement dans les modèles et la plateforme à travers la calibration, la robustesse de queue longue, la surveillance de dérive et les politiques explicites d'abstention et d'escalade.
Traiter HITL comme une dépendance d'exécution peut introduire de la latence et de la fragilité qui sont incompatibles avec la sécurité véhiculaire en temps réel et la continuité opérationnelle.
Là où HITL est précieux, c'est dans la boucle asynchrone : le travail qui se passe hors temps réel et ne nécessite pas de réponse immédiate. Cela inclut l'amélioration des données d'entraînement, la révision des cas difficiles, l'audit des résultats et la gestion des flux d'escalade rares qui nécessitent du contexte et du jugement. Le bon cadrage n'est pas « IA vs humains », mais une division du travail fondée sur des principes : automation pour la boucle temps réel, et humains pour l'apprentissage, la gouvernance et les cas limites véritablement ambigus.
Un exemple : un changement de voie avec un véhicule s'approchant rapidement dans l'angle mort lors d'une fusion. La fenêtre de coaching est une fraction de seconde. Le système doit alerter maintenant, et le gestionnaire doit pouvoir auditer plus tard.
En termes plus simples : Agir maintenant, parler plus tard.
HITL : « dans la boucle » vs « sur la boucle »
En pratique, il est critique de distinguer l'humain dans la boucle, où les humains doivent approuver les décisions avant l'action, de l'humain sur la boucle, où les humains supervisent le comportement système, auditent les résultats et n'interviennent que lorsque explicitement escaladé. Pour le coaching de conducteur en une fraction de seconde et la prévention de collision, un modèle sur la boucle est souvent la seule approche viable. Le système doit opérer de manière autonome en temps réel à la périphérie, tout en exposant des preuves auditables, des signaux de confiance et des chemins d'escalade bien définis pour le petit nombre de cas qui nécessitent un jugement humain.
HITL livre le plus de valeur hors du chemin de contrôle temps réel, incluant :
- Entraînement et étiquetage de scénarios difficiles ou de queue longue
- Audits périodiques et application de politiques pour assurer l'intégrité des modèles et la conformité
- Flux de gestion d'exceptions pour les événements de risque élevé où la révision humaine contextuelle ajoute du signal
Positionner HITL comme une exigence universelle d'exécution peut introduire de la latence, des goulots d'étranglement opérationnels et des contraintes d'évolutivité, et signale souvent une architecture qui n'a pas été conçue pour une performance déterministe sous des conditions de flotte du monde réel.
Pourquoi cela importe pour les dirigeants de flotte : c'est la différence entre un coaching qui change le comportement dans le moment et un processus de révision que les conducteurs ignorent et que les gestionnaires ne peuvent pas faire évoluer.
Lors de l'évaluation de l'IA de flotte, posez trois questions :
- Quelles décisions s'exécutent sur le véhicule à la périphérie ?
- Comment le système aide-t-il à contrôler les faux positifs, pour que les conducteurs et gestionnaires n'ignorent pas ?
- Quelles preuves sont sauvegardées pour que le coaching et les enquêtes soient cohérents et défendables ?
Pourquoi HITL ne livre pas de résultats en temps réel
Pour le coaching temps réel, la contrainte est simple : la boucle de rétroaction est typiquement inférieure à une seconde. Attendre une révision humaine introduit des secondes à minutes de délai et brise le modèle de confiance pour les conducteurs. La rétroaction doit être opportune et cohérente pour influencer le comportement.
La connectivité ne peut non plus être assumée, et les allers-retours nuage ne peuvent pas être le facteur limitant pour l'expérience sur route.
C'est pourquoi l'intelligence périphérie d'abord importe : le traitement sur appareil livre une faible latence, la disponibilité même hors ligne, et une performance prévisible sous des contraintes de coût et de bande passante. Alors que les SoCs de périphérie (ex. classe NVIDIA/Qualcomm) continuent d'évoluer, la frontière de ce qui peut s'exécuter sur appareil s'étend. Mais indépendamment du progrès matériel, le principe architectural demeure : les boucles de sécurité temps réel sont mieux fermées à la périphérie.
Réalité opérationnelle : l'intelligence de périphérie est ce qui maintient le coaching cohérent à travers les zones mortes, dépôts, tunnels et routes éloignées, exactement là où les flottes ne peuvent pas se permettre une sécurité au mieux effort.
Précision vs valeur : « IA universelle » vs ingénierie pratique de résultats
Un piège commun dans la conception de système IA est de traiter la qualité comme une métrique scalaire unique, telle que la précision globale, la précision ou le score F1, et d'assumer que des scores plus élevés se traduisent directement en de meilleurs résultats. En pratique, la valeur livrée dépend des compromis de point opérationnel (faux positifs vs faux négatifs), calibration, comportement de queue longue et, critiquement, si le système peut agir en temps réel sous des conditions du monde réel. Un modèle peut atteindre une haute précision moyenne et toujours échouer opérationnellement s'il est mal calibré, se dégrade silencieusement sous un changement de distribution ou submerge les utilisateurs avec des faux positifs.
Cette distinction souligne pourquoi la valeur n'est pas créée par la précision seule, mais par l'architecture d'exécution. Beaucoup d'applications de sécurité et opérations ne nécessitent pas une prédiction parfaite pour livrer des résultats significatifs, mais elles nécessitent un comportement prévisible, une latence bornée et une signalisation de confiance claire au moment où les décisions importent. Ces exigences sont souvent impossibles à rencontrer quand l'inférence, la prise de décision ou la validation est conditionnée par des allers-retours nuage ou une approbation humaine.
Les systèmes les plus efficaces suivent donc une conception périphérie d'abord :
- Intelligence temps réel, sur véhicule qui livre de manière autonome coaching et atténuation de risque dans des boucles inférieures à une seconde
- Escalade sélective pour des cas véritablement ambigus ou à haut risque, où le jugement humain ajoute du signal plutôt que du délai
- Une boucle d'apprentissage asynchrone, incluant HITL, utilisée pour raffiner les modèles au fil du temps sans bloquer la performance temps réel
Dans ce cadrage, HITL améliore l'apprentissage et la gouvernance, mais l'intelligence de périphérie est ce qui crée une amélioration de performance immédiate et cumulative. Les systèmes qui dépendent de HITL comme mécanisme principal finissent souvent par optimiser pour la révision, pas les résultats.
Bénéfice gestionnaire : c'est la différence entre le programme de sécurité potentiel qui réduit le risque semaine après semaine et celui qui génère plus de séquences à réviser sans changement de comportement mesurable.
À quoi ressemble la « fiabilité par conception » dans les systèmes déployés
Le modèle le plus efficace est d'intégrer la fiabilité dans le système de périphérie temps réel, et d'utiliser les humains là où ils créent un maximum d'effet de levier : qualité des données d'entraînement, audits, révision de cas difficiles et flux d'escalade rares où le contexte et le jugement importent. Un système IA de haute qualité devrait aussi être calibré et sélectif. Il devrait savoir quand il est confiant, quand s'abstenir et quand escalader, pour que les humains se concentrent sur des exceptions véritablement ambiguës ou à enjeux élevés plutôt que sur des événements de routine.
Dans l'IA physique déployée, cela se traduit en capacités techniques et systèmes concrètes que les dirigeants de flotte peuvent reconnaître en pratique : preuves prêtes pour audit, contrôle de bruit, stabilité prouvable et déploiements sûrs à l'échelle.
Mode ombre (déploiements sûrs)
Une technique pratique est le mode ombre : exécuter des modèles candidats sur appareil qui ne sont pas encore prêts pour production, comparer leurs sorties contre les systèmes de production et résultats, et utiliser ce signal pour faire ressortir les cas limites et régressions. Le mode ombre permet aux équipes d'apprendre des distributions du monde réel en sécurité, sans exposer les conducteurs ou flottes à un comportement expérimental dans la boucle live.
Exploration de données + infrastructure de cas limites (stabilité prouvable)
Dans l'IA du monde physique, le progrès est dominé par la queue longue. C'est pourquoi l'investissement dans l'infrastructure d'exploration de données importe : systèmes qui peuvent automatiquement découvrir des scénarios rares, trancher la performance par condition (nuit, pluie, occlusion, géométrie) et alimenter des ensembles de données ciblés de retour dans l'entraînement et l'évaluation. C'est souvent la différence entre « bonne précision moyenne » et performance fiable du monde réel.
Amélioration continue + R&D (contrôle de bruit au fil du temps)
Un différenciateur clé dans l'IA physique déployée est la boucle d'amélioration continue : instrumentation, détection de dérive, exploration de modes d'échec, ré-entraînement ciblé et tests de régression. Ce n'est pas une sortie de modèle unique. C'est un investissement R&D continu pour étendre régulièrement la couverture et la fiabilité au fil du temps.
Optimisation de périphérie (performance prouvée sur le terrain)
L'optimisation de périphérie est sa propre discipline : quantification, distillation, architecture efficace et ajustement soigneux de point opérationnel pour que les modèles rencontrent les limites de latence p95 et de puissance sur les SoCs de périphérie. La contrainte n'est pas juste la vitesse. C'est une performance prévisible et la disponibilité dans des conditions du monde réel.
OTA + itération rapide (déploiements sûrs avec garde-fous)
Un différenciateur clé pour les systèmes déployés est la vitesse d'itération. L'infrastructure OTA permet des déploiements étagés, des correctifs rapides et des mises à jour ciblées pour que quand de nouveaux cas limites émergent ou les distributions changent, le système puisse s'adapter sans attendre de longs cycles de sortie. Combiné avec des tests de régression et surveillance, cela devient une boucle fiable « mesurer → apprendre → mettre à jour » avec des garde-fous qui protègent le temps de fonctionnement et la confiance des conducteurs.
Conclusion
Du point de vue systèmes, la question n'est pas si les humains devraient être impliqués, mais où ils fournissent le plus haut effet de levier. Le coaching temps réel dépend d'une automation déterministe, à faible latence opérant au point d'action. L'implication humaine est mieux appliquée à l'entraînement de modèles, aux audits de performance et à la gestion d'exceptions. Positionner HITL comme une exigence universelle confond la supervision avec le chemin de contrôle temps réel et peut masquer si un système IA est véritablement architecturé pour opérer de manière fiable et à l'échelle dans des environnements physiques.


Vous voulez protéger les conducteurs et réduire les coûts ?
Ce n'est pas une question trompeuse. Voyez par vous-même avec une démo.