Vertrouwen opbouwen in Vloot-AI: Real-Time Preventie, Betrouwbaarheid & Menselijk Toezicht Waar Het Ertoe Doet
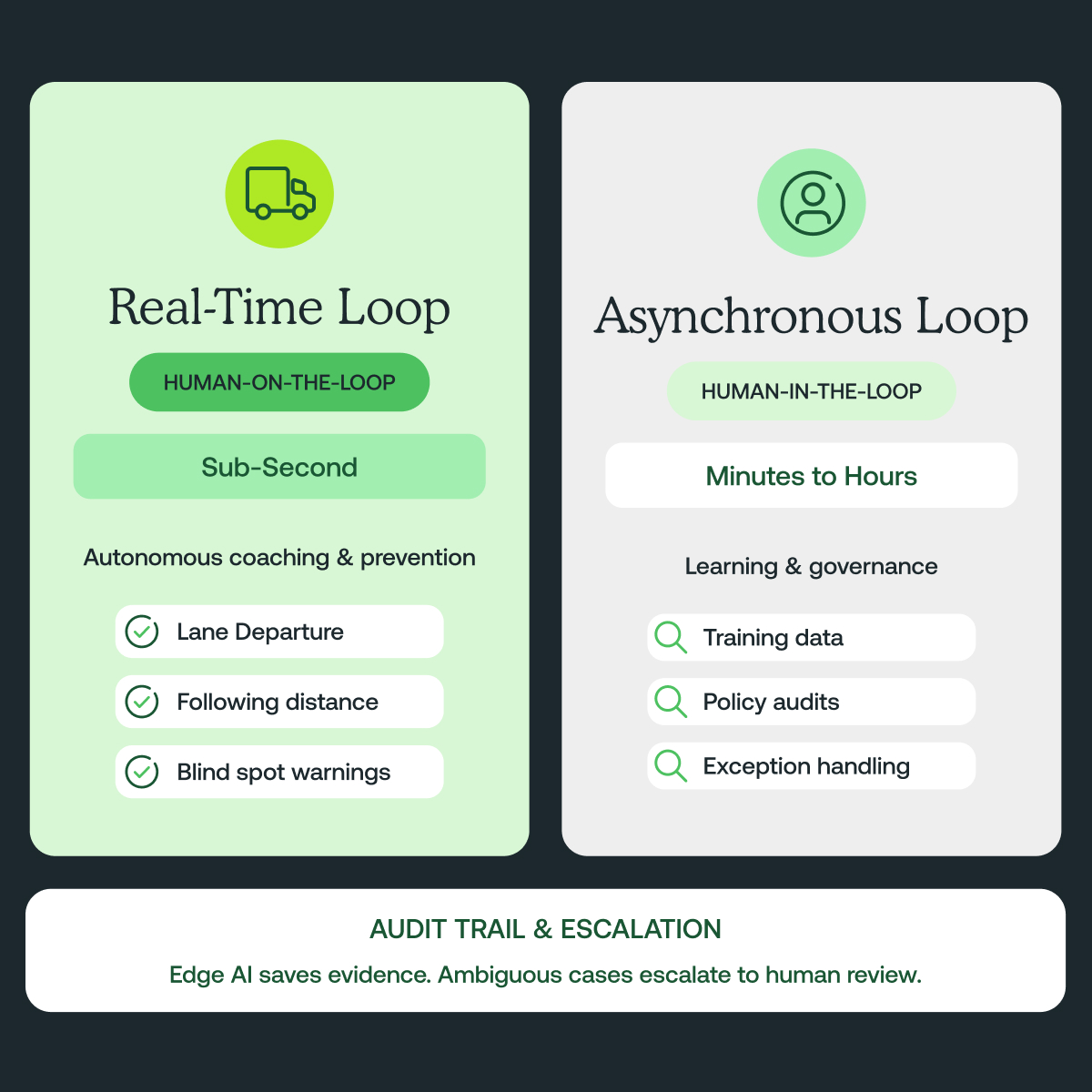
Human-in-the-loop (HITL) speelt een kritieke rol in modelvalidatie, auditing en continue verbetering voor vlootveiligheid en -operaties. Echter, in real-time, veiligheidskritieke scenario's is HITL niet geschikt als primaire controlepad vanwege onvermijdelijke latentie en operationele beperkingen. In rijsituaties in de echte wereld zijn beslissingsloops sub-seconde, is connectiviteit intermitterend, en moet risicomitigatie voorspelbaar en consistent uitgevoerd worden op het voertuig, aan de rand. Ontworpen voor hoogbetrouwbare, real-time werking hebben deze architecturen bewezen te helpen bij het verminderen van vermijdbare incidenten, het reduceren van video-review werkbelasting, en het ondersteunen van snellere onderzoeken.
Voor real-time bestuurdercoaching en botsingspreventie kan een mens niet "in de loop" zijn tijdens runtime. Systeembetrouwbaarheid moet direct in de modellen en het platform geïntegreerd worden door kalibratie, long-tail robuustheid, drift monitoring, en expliciete beleidsregels voor onthouding en escalatie.
Het behandelen van HITL als een runtime afhankelijkheid kan latentie en fragiliteit introduceren die incompatibel zijn met real-time voertuigveiligheid en operationele continuïteit.
Waar HITL waardevol is, is in de asynchrone loop: werk dat buiten real-time gebeurt en geen onmiddellijke respons vereist. Dit omvat het verbeteren van trainingsdata, het beoordelen van moeilijke gevallen, het auditeren van resultaten, en het afhandelen van zeldzame escalatieworkflows die context en oordeel vereisen. De juiste framing is niet "AI versus mensen," maar een principiële taakverdeling: automatisering voor de real-time loop, en mensen voor leren, governance, en echt dubbelzinnige randgevallen.
Een voorbeeld: een baanwisseling met een snel naderend voertuig in de dode hoek tijdens het invoegen. Het coachingsvenster is een fractie van een seconde. Het systeem moet nu waarschuwen, en de manager moet later kunnen auditeren.
In eenvoudige termen: Handel Nu, Praat Later.
HITL: "in de loop" versus "op de loop"
In de praktijk is het kritiek om onderscheid te maken tussen human-in-the-loop, waar mensen beslissingen moeten goedkeuren voordat er actie wordt ondernomen, en human-on-the-loop, waar mensen systeemgedrag overzien, resultaten auditeren, en alleen ingrijpen wanneer expliciet geëscaleerd. Voor sub-seconde bestuurdercoaching en botsingspreventie is een on-the-loop model vaak de enige haalbare benadering. Het systeem moet autonoom werken in real-time aan de rand, terwijl het auditeerbaar bewijs, betrouwbaarheidssignalen, en goed gedefinieerde escalatiepaden blootlegt voor het kleine aantal gevallen dat menselijk oordeel vereist.
HITL levert de meeste waarde buiten het real-time controlepad, waaronder:
- Training en labeling van moeilijke of long-tail scenario's
- Periodieke audits en beleidshandhaving om modelintegriteit en compliance te waarborgen
- Exception handling workflows voor verhoogde risicogebeurtenissen waar contextuele menselijke review signaal toevoegt
Het positioneren van HITL als een universele runtime vereiste kan latentie, operationele knelpunten, en schaalbaarheidsbeperking introduceren, en signaleert vaak een architectuur die niet geëngineered is voor deterministische prestaties onder echte vlootcondities.
Waarom dit belangrijk is voor vlootleiders: het is het verschil tussen coaching die gedrag in het moment verandert en een reviewproces dat bestuurders negeren en managers niet kunnen opschalen.
Bij het evalueren van vloot-AI, stel drie vragen:
- Welke beslissingen draaien op het voertuig aan de rand?
- Hoe helpt het systeem valse positieven te beheersen, zodat bestuurders en managers niet afhaken?
- Welk bewijs wordt bewaard zodat coaching en onderzoeken consistent en verdedigbaar zijn?
Waarom HITL Geen Real-Time Resultaten Levert
Voor real-time coaching is de beperking eenvoudig: de feedbackloop is typisch sub-seconde. Wachten op een menselijke review introduceert seconden-tot-minuten vertraging en breekt het vertrouwensmodel voor bestuurders. Feedback moet tijdig en consistent zijn om gedrag te beïnvloeden.
Connectiviteit kan ook niet worden aangenomen, en cloud roundtrips kunnen niet de beperkende factor zijn voor de onderweg-ervaring.
Daarom is edge-first intelligence belangrijk: on-device processing levert lage latentie, beschikbaarheid zelfs offline, en voorspelbare prestaties onder kosten- en bandbreedtebeperkingen. Terwijl edge SoCs (bijvoorbeeld NVIDIA/Qualcomm klasse) blijven evolueren, breidt de grens van wat op apparaat kan draaien uit. Maar ongeacht hardware vooruitgang blijft het architecturale principe: real-time veiligheidsloops worden het beste gesloten aan de rand.
Operationele realiteit: edge intelligence is wat coaching consistent houdt door dode zones, depots, tunnels, en afgelegen routes, precies waar vloten zich geen best-effort veiligheid kunnen veroorloven.
Nauwkeurigheid versus waarde: "one-size-fits-all AI" versus praktische outcome engineering
Een veelvoorkomende valkuil in AI-systeemontwerp is kwaliteit behandelen als een enkele scalaire metriek, zoals algehele nauwkeurigheid, precisie, of F1 score, en aannemen dat hogere scores direct vertalen naar betere resultaten. In de praktijk hangt geleverde waarde af van operating-point tradeoffs (valse positieven versus valse negatieven), kalibratie, long-tail gedrag, en kritiek, of het systeem kan handelen in real-time onder echte wereldcondities. Een model kan hoge gemiddelde nauwkeurigheid behalen en nog steeds operationeel falen als het slecht gekalibreerd is, stil degradeert onder distributieverschuiving, of gebruikers overweldigt met valse positieven.
Dit onderscheid benadrukt waarom waarde niet alleen door nauwkeurigheid wordt gecreëerd, maar door uitvoeringsarchitectuur. Veel veiligheids- en operatietoepassingen vereisen geen perfecte voorspelling om betekenisvolle resultaten te leveren, maar ze vereisen wel voorspelbaar gedrag, begrensde latentie, en duidelijke betrouwbaarheidssignalering op het moment dat beslissingen ertoe doen. Die vereisten zijn vaak onmogelijk te vervullen wanneer inferentie, besluitvorming, of validatie beperkt wordt door cloud roundtrips of menselijke goedkeuring.
De meest effectieve systemen volgen daarom een edge-first ontwerp:
- Real-time, on-vehicle intelligence die autonoom coaching en risicomitigatie levert in sub-seconde loops
- Selectieve escalatie voor echt dubbelzinnige of hoog-risico gevallen, waar menselijk oordeel signaal toevoegt in plaats van vertraging
- Een asynchrone leerloop, inclusief HITL, gebruikt om modellen over tijd te verfijnen zonder real-time prestaties te blokkeren
In deze framing verbetert HITL leren en governance, maar edge intelligence is wat onmiddellijke, samengestelde prestatieverbetering creëert. Systemen die vertrouwen op HITL als primair mechanisme eindigen vaak met optimaliseren voor review, niet resultaten.
Manager voordeel: dit is het verschil tussen het potentiële veiligheidsprogramma dat risico week na week vermindert en een dat meer beeldmateriaal genereert om te reviewen zonder meetbare gedragsverandering.
Hoe "betrouwbaarheid door ontwerp" eruitziet in geïmplementeerde systemen
Het meer effectieve patroon is om betrouwbaarheid in het real-time edge systeem te engineeren, en mensen te gebruiken waar ze maximale hefboomwerking creëren: trainingsdatakwaliteit, audits, moeilijke-case review, en zeldzame escalatieworkflows waar context en oordeel belangrijk zijn. Een hoogkwalitatief AI-systeem moet ook gekalibreerd en selectief zijn. Het moet weten wanneer het zeker is, wanneer het moet afzien, en wanneer het moet escaleren, zodat mensen zich richten op echt dubbelzinnige of hoge-inzet uitzonderingen in plaats van routinegebeurtenissen.
In geïmplementeerde Physical AI vertaalt dat zich naar concrete technische en systeemmogelijkheden die vlootleiders in de praktijk kunnen herkennen: audit-klaar bewijs, ruiscontrole, bewezen stabiliteit, en veilige rollouts op schaal.
Shadow mode (veilige rollouts)
Een praktische techniek is shadow mode: draai kandidaat-modellen on-device die nog niet productie-klaar zijn, vergelijk hun outputs tegen productiesystemen en resultaten, en gebruik dat signaal om hoekgevallen en regressies bloot te leggen. Shadow mode laat teams veilig leren van real-world distributies, zonder bestuurders of vloten bloot te stellen aan experimenteel gedrag in de live loop.
Data mining + corner-case infrastructuur (bewezen stabiliteit)
In fysieke-wereld AI wordt vooruitgang gedomineerd door de long tail. Daarom is investering in data mining infrastructuur belangrijk: systemen die automatisch zeldzame scenario's kunnen ontdekken, prestaties per conditie kunnen segmenteren (nacht, regen, occlusie, geometrie), en gerichte datasets kunnen terugvoeren naar training en evaluatie. Dit is vaak het verschil tussen "goede gemiddelde nauwkeurigheid" en betrouwbare real-world prestaties.
Continue verbetering + R&D (ruiscontrole over tijd)
Een belangrijke differentiator in geïmplementeerde Physical AI is de continue verbeteringsloop: instrumentatie, drift detectie, mining van faalwijzen, gerichte hertraining, en regressietesting. Het is geen eenmalige modelrelease. Het is voortdurende R&D investering om dekking en betrouwbaarheid over tijd gestaag uit te breiden.
Edge optimalisatie (bewezen prestaties in het veld)
Edge optimalisatie is zijn eigen discipline: kwantisatie, distillatie, efficiënte architectuur, en zorgvuldige operating-point tuning zodat modellen p95 latentie en stroomlimieten op edge SoCs halen. De beperking is niet alleen snelheid. Het is voorspelbare prestaties en beschikbaarheid in real-world condities.
OTA + snelle iteratie (veilige rollouts met waarborgen)
Een belangrijke differentiator voor geïmplementeerde systemen is iteratiesnelheid. OTA infrastructuur maakt gefaseerde rollouts, snelle hotfixes, en gerichte updates mogelijk zodat wanneer nieuwe hoekgevallen opkomen of distributies verschuiven, het systeem kan aanpassen zonder te wachten op lange release cycli. Gecombineerd met regressietests en monitoring wordt dit een betrouwbare "meet → leer → update" loop met waarborgen die uptime en bestuurdersvertrouwen beschermen.
Sluiting
Vanuit een systeemperspectief is de vraag niet of mensen betrokken moeten zijn, maar waar ze de hoogste hefboomwerking bieden. Real-time coaching hangt af van deterministische, lage-latentie automatisering die opereert op het punt van actie. Menselijke betrokkenheid wordt het beste toegepast op modeltraining, prestatieaudits, en exception handling. Het positioneren van HITL als een universele vereiste conflateert toezicht met het real-time controlepad en kan verhullen of een AI-systeem echt gearchitecteerd is om betrouwbaar en op schaal te opereren in fysieke omgevingen.


Wilt u chauffeurs beschermen en de kosten verlagen?
Dat is geen moeilijke vraag. Overtuig uzelf met een demo.